
중국의 AI 스타트업 딥 시크가 저렴한 비용으로 미국의 AI 모델과 비슷하거나 더 뛰어난 성능을 보여주면서, 미국의 AI 산업에 위기감을 불러일으키고 있습니다.
이로 인해 미국 기업들은 막대한 투자 비용의 정당성을 고민하게 되었고, AI 패권 경쟁에서의 전략적 방향성에 대한 의문이 제기되고 있습니다. 이러한 상황은 미국의 AI 개발자들에게 큰 충격을 주며, 향후 AI 시장의 구조적 변화를 예고하고 있습니다.
중국산 AI의 등장중국의 딥 시크라는 스타트업이 오픈 AI와 유사한 AI모델을 개발하여 주목받고 있습니다. 이 모델들은 저렴한 비용으로 미국의 AI모델들과 비슷하거나 더 나은 성능을 보여주고 있습니다. 딥 시크의 오픈 소스 모델 딥 시크버전 2는 오픈 소스로 개발되어 많은 개발자들에게 알려졌습니다. 오픈 소스란 AI모델의 모든 소스 코드와 아키텍처를 공개하여 누구나 수정하고 사용할 수 있도록 하는 것이며 딥 시크는 오픈 소스의 사명을 지키며, 가성비가 뛰어난 모델을 제공하고 있습니다. 딥 시크의 추론 비용은 100만 토큰당 180원으로, 메타의 라마 3 모델보다 저렴하다고 합니다. 딥 시크버전 3의 개발 비용은 580억 달러로, 메타의 비용의 1/10에 불과합니다. 이 모델은 저성능 칩을 사용하여도 뛰어난 성능을 발휘하고 있습니다.

딥 시크 R1 모델의 성능딥 시크R1 모델은 오픈 AI의 최신 모델과 비슷한 성능을 보여줍니다. 이 모델은 추론 기능과 실시간 웹 검색 기능을 모두 제공하며, 무료로 사용할 수 있습니다. 현재 미국에서 이러한 기능을 제공하는 AI는 퍼플렉시티 외에는 없다고 하네요.
API 비용과 상업적 사용딥 시크는 API비용을 매우 저렴하게 제공하며, 상업적 사용도 가능합니다. 오픈 AI와 비교하여 사용 조건이 간단하고, 수익을 공유할 필요가 없습니다.
중국의 다른 기업들도 저렴한 비용으로 AI모델을 개발하고 있으며, 바이트댄스의 모델은 딥 시크보다 20% 더 저렴합니다. 이러한 경쟁은 가성비 전쟁을 촉발하고 있습니다. 미국의 위기감미국 AI업계는 중국의 저렴한 AI모델에 대한 경계심을 느끼고 있습니다. 딥 시크의 성능과 비용은 미국의 AI기업들에게 큰 충격을 주고 있습니다.
미국 AI 기업의 대응미국의 AI기업들은 딥 시크의 저비용 모델에 대응하기 위해 비용 절감 경쟁에 나설 것으로 예상됩니다. 메타와 마이크로소프트는 각각 650억 달러와 800억 달러를 투자하겠다고 발표했습니다.
딥 시크의 성공은 미국 AI기업들에게 혁신의 필요성을 일깨우고 있습니다. 중국산 AI의 위협은 앞으로도 계속해서 중요한 이슈가 될 것으로 보이네요...
딥시크(Deepseek)의 최근 혁신은 미국 주식 시장에 큰 충격을 주며 AI 산업의 판도를 변화시키고 있습니다. 다음은 딥시크의 파괴력과 그로 인한 영향에 대한 요약입니다.
딥시크의 주요 특징 및 성과
- 비용 효율성: 딥시크는 기존 AI 모델을 개발하는 데 드는 비용의 10분의 1 수준으로, 비슷한 성능을 제공하는 모델을 개발했습니다. 이는 AI 기술의 접근성을 크게 향상시킵니다.
- 성능 향상: 딥시크의 R1 모델은 OpenAI의 최신 모델과 유사한 성능을 보여주며, 메타의 Llama 4를 초월하는 성과를 달성했습니다.
- 앱스토어 1위: 딥시크는 미국 앱스토어에서 챗GPT를 제치고 다운로드 수 1위를 기록하며, 기술력이 실용적임을 입증했습니다.
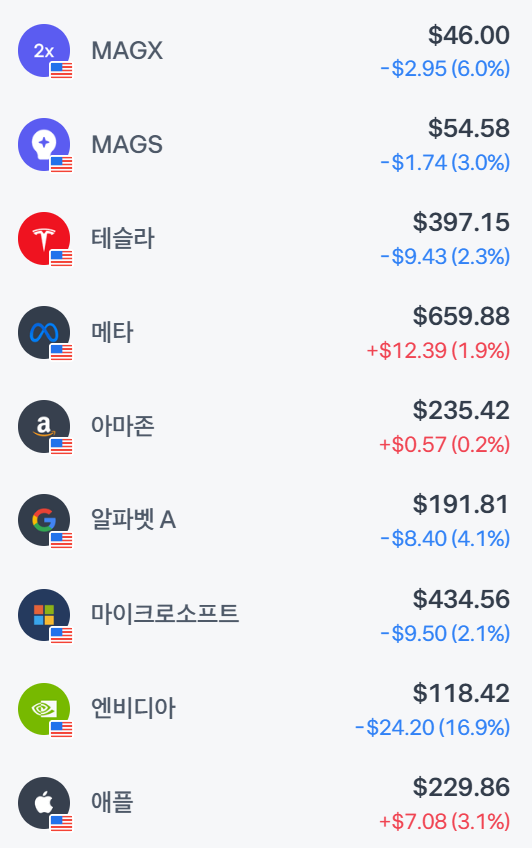
시장 반응 및 영향
- 주식 시장 급락: 딥시크 쇼크로 인해 나스닥 종합지수는 3.35% 하락했고, 엔비디아 주가는 하루 만에 17% 급락했습니다. 이는 AI 관련 주식에 대한 투자 심리를 크게 위축시키고 있습니다.
- AI 버블 붕괴 우려: 미국 내 AI 기업들이 딥시크의 성과에 위협을 느끼며, AI 산업에서의 거품이 꺼질 가능성이 제기되고 있습니다.
- 글로벌 경쟁 심화: 딥시크의 혁신은 중국과 미국 간의 AI 기술 격차를 줄이며, 글로벌 AI 시장에서의 경쟁이 더욱 치열해질 것으로 예상됩니다.
딥시크는 저비용 고성능 AI 모델 개발로 인해 미국 AI 시장에 큰 파장을 일으키고 있으며, 이는 향후 AI 산업 구조와 기업 가치 평가에 중대한 영향을 미칠 것으로 보입니다. 이러한 변화는 투자자들에게 새로운 기회를 제공하는 동시에, 기존 AI 강자들에게는 도전 과제가 될 것입니다.

딥시크(DeepSeek)가 엔비디아(NVIDIA)와의 경쟁에서 우위를 차지하는 주요 요인은 다음과 같습니다.
1. 비용 효율성
딥시크는 기존 AI 모델보다 30~50배 저렴한 비용으로 AI 모델을 개발할 수 있는 능력을 보유하고 있습니다. 예를 들어, 딥시크-R1 모델은 약 57만 6,000달러의 비용으로 학습되었으며, 이는 메타의 Llama 3 모델 학습 비용의 10분의 1 수준입니다. 이러한 비용 절감은 기업들이 딥시크의 기술을 선택하는 데 중요한 요소로 작용하고 있습니다.
2. 기술 혁신
딥시크는 여러 혁신적인 기술을 통해 성능과 효율성을 크게 향상시켰습니다. 주요 기술로는
- 멀티에드 잠재 어텐션(MLA): 메모리 사용량을 대폭 줄여 효율적인 모델 운영을 가능하게 합니다.
- DeepSeekMoE: 특정 모델만 활성화하여 계산 효율성을 높이는 방식으로, 계산 비용을 절감합니다.
- 강화학습 기반 자기 학습 능력: 모델이 스스로 학습하고 개선할 수 있는 능력을 강화하여 높은 성능을 달성합니다.
3. 소프트웨어 최적화
딥시크는 엔비디아 H800 GPU를 활용하여 훈련했지만, 소프트웨어 최적화를 통해 짧은 시간 안에 모델을 완성할 수 있었습니다. 이는 하드웨어 의존도를 줄이고, 소프트웨어만으로도 고성능 AI 개발이 가능하다는 점에서 엔비디아에 대한 위협이 됩니다.
4. 시장 반응 및 영향
딥시크의 성공적인 모델 출시는 엔비디아의 주가에 직접적인 영향을 미쳤으며, 엔비디아는 딥시크의 등장으로 인해 고객들이 기존 칩을 보다 효율적으로 활용하게 되어 새로운 수요가 둔화될 가능성이 제기되었습니다26. 이러한 변화는 AI 칩 시장에서 엔비디아의 독점적 지위에 도전하는 요소로 작용하고 있습니다.
딥시크의 저비용 고효율 전략과 기술적 혁신은 AI 시장에서의 경쟁 구도를 변화시키고 있으며, 이는 엔비디아와 같은 기존 강자들에게 심각한 도전 과제가 되고 있습니다.
딥시크(DeepSeek)의 AI 모델이 메타의 Llama 4를 능가하는 이유는 여러 가지 기술적, 경제적 요소에 기인합니다.
1. 비용 효율성
딥시크의 V3 모델은 약 557만 달러의 비용으로 훈련되었습니다. 이는 메타의 Llama 3.1 모델이 추정한 5억 달러 이상의 훈련 비용에 비해 훨씬 경제적입니다. 이러한 비용 절감은 딥시크가 저사양 GPU를 사용하여도 성능을 극대화할 수 있도록 했습니다.
2. 모델 규모 및 데이터셋
딥시크 V3는 6710억 개의 매개변수를 가지고 있으며, 이는 Llama 3.1의 4050억 개보다 약 1.5배 더 큰 규모입니다. 또한, V3는 14조 8000억 개의 토큰으로 구성된 방대한 데이터셋으로 사전 훈련되어 다양한 작업에서 높은 성능을 발휘합니다.
3. 성능 벤치마크
딥시크 V3는 여러 벤치마크 테스트에서 메타의 Llama 시리즈 및 오픈AI의 GPT 모델을 초월하는 성과를 보였습니다. 예를 들어, 코딩 및 언어 능력 평가에서 높은 정확도를 기록하며, Llama 3.1과 비교해도 우수한 결과를 나타냈습니다.
4. 혁신적인 기술 활용
딥시크는 최신 기술을 활용하여 적은 양의 GPU로도 높은 성능을 이끌어내는 데 성공했습니다. 이는 딥시크가 AI 모델을 훈련시키는 데 필요한 컴퓨팅 리소스를 대폭 줄일 수 있게 해주었습니다.
이러한 요소들은 딥시크가 메타의 Llama 4와 같은 기존 강자들에 비해 경쟁력을 갖추게 하는 주요 요인으로 작용하고 있습니다. 딥시크는 비용 효율성과 성능 모두에서 우위를 점하며 AI 시장에서 새로운 패러다임을 제시하고 있습니다.
'미국주식' 카테고리의 다른 글
| Eason Technology Limited (이전 이름: Dunxin Financial Holdings) 티커 DXF (2) | 2025.01.28 |
|---|---|
| 플래닛 이미지 인터내셔널 (티커 YIBO) (2) | 2025.01.28 |
| 아케로 테라퓨틱스(Akero Therapeutics, AKRO) (3) | 2025.01.27 |
| 오로라 모바일(Aurora Mobile, ADR, 티커: JG) (6) | 2025.01.27 |
| 온코네틱스(Onconetix, Inc., 티커: ONCO) (1) | 2025.01.27 |



